Event Sourcing for the poor or one PostgreSQL is enough for you
Introduction
There are two ways to store data. You can store it in its final state right away or keep a list of events that, when processed sequentially, yield that final state. The latter is known as Event Sourcing.
Event Sourcing is an approach to working with events. You use a series of events representing changes, and based on them, you reconstruct the state of your object.
In today's world, any business application will eventually have to answer the questions - who changed what and when? Can the data be rolled back to a previous state? Or, for example, how can you view a snapshot of the data as it was a week ago? Therefore, starting something new without considering the architecture from the outset, in my opinion, is negligent.
However, there is the flip side - speed and experience. Even with the knowledge and experience on how to build such systems correctly, I prefer not to start a project with infrastructure construction. Having a good message broker and a fast data storage is essential for working with Event Sourcing. Often, the combination used is Kafka + RabbitMQ + MongoDB/Elastic. This setup works well, but I don't want to set up all these complex systems locally just to start writing code. And they aren't necessary until your users generate hundreds of thousands of requests per second and you face scaling challenges.
Therefore, my initial criteria for finding a good solution were:
I want to have minimal infrastructure
I want to have a mature application architecture from the start
It should be quick to develop
It should be clear and simple, meaning the list of technologies should be minimal
This is how I came to have an endless love for PostgreSQL.
Not Only Event Sourcing
Working with events alone is not enough; it's also necessary to reconsider the approach to working with APIs. There can be much debate, with books, projects, and talks on how to properly build interactions between clients and applications. But in my opinion, CQRS is the way to go. Especially considering the fact that, together with an event-driven architecture, it works perfectly.
Command and Query Responsibility Segregation (CQRS) is a principle or paradigm that separates the handling of queries and commands for data processing.
Simply put, an API is divided into two types of requests: mutating and querying data.
Along with an event-driven approach, this results in essentially one mutating request to insert events and a number of necessary and diverse data read requests.
Additionally, it's important to understand that data representation and reading do not have to be executed in a classical manner. They can and should be closer to Domain-Driven Design (DDD).
Domain-Driven Design (DDD) is a set of principles and patterns aimed at creating optimal object systems. It involves creating software abstractions called domain models.
Of course, there's no sense in rigidly adhering to the entirety of Evans' DDD and implementing it in all its details, but I will borrow some practices from this approach.
It's also important to understand that overall, we will be leveraging the Event Streaming pattern. However, only partially and without delving deeply into details. The point is that the combination of Event Storing + Event Streaming + CQRS gives the result I am aiming for in terms of the application.
Event Streaming is the process of continuously capturing and storing events as they occur in a system. These events can then be processed and analyzed in real-time or stored for later analysis.
High-Level Implementation Idea
The idea is quite simple:
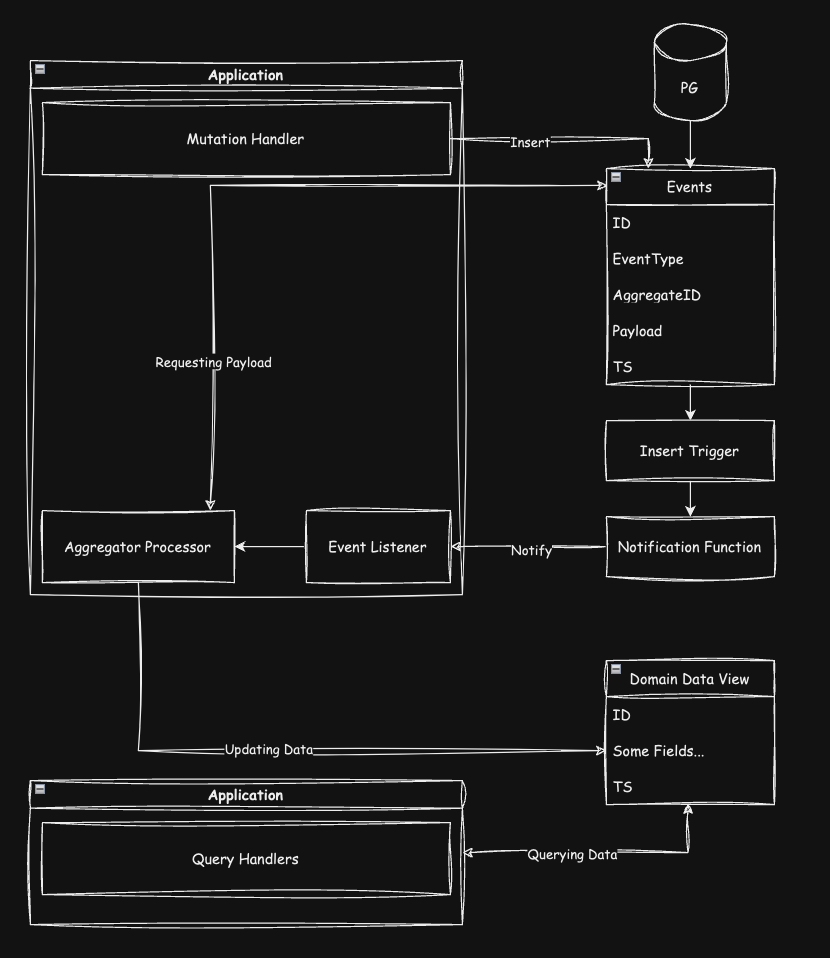
If Explained Simply:
We have an events table.
A trigger on the events table executes a function to send a message.
On the application side, there's a listener for the message topic from the events table. Yes, PostgreSQL has the notify/listen functionality.
Based on the received message, some event processing logic requests the event payload from the database using the event identifier and updates one or more views as needed.
Additionally, on the application side, all data reading methods work only with the data view tables.
With this approach, we have no restrictions on the data structure organization; we can store everything in JSON if we want, or fully normalize it, depending on the requirements.
Moving to Implementation
The complete working example is available in the GitHub repository.
I will implement the example in Go, using a set of libraries that I find convenient and enjoyable, but the core idea can be realized in any way you prefer and is not dependent on my specific choices.
Create a new project and use cobra by spf13 to initialize the entry point..
31mkdir example-event-sourcing && cd example-event-sourcing2go mod init example-event-sourcing3go get github.com/spf13/cobra
It's better to install cobra-cli and run:
41go install github.com/spf13/cobra-cli@latest2cobra-cli init4cobra-cli add run
We won't go into detailed descriptions and command setups now; let's continue building the structure.
Configuration
First, it would be good to teach our application to read some configuration parameters from a .env. file. For this, viper by spf13 will help, along with a separate package within the application to simplify my life.
11go get github.com/spf13/viper
Place this file in the project at: internal/config/config.go.
471package config2
3import (4 "github.com/spf13/viper"5 "log"6)7
8// EnvConfigs Initialize this variable to access the env values9var EnvConfigs *envConfigs10
11// InitEnvConfigs We will call this in main.go to load the env variables12func InitEnvConfigs() {13 EnvConfigs = loadEnvVariables()14}15
16// struct to map env values17type envConfigs struct {18 AppServerPort string `mapstructure:"APP_SERVER_PORT"`19 DbDsn string `mapstructure:"DB_DSN"`20}21
22// Call to load the variables from env23func loadEnvVariables() (config *envConfigs) {24 // Tell viper the path/location of your env file. If it is root just add "."25 viper.AddConfigPath(".")26
27 // Tell viper the name of your file28 viper.SetConfigName(".env")29
30 // Tell viper the type of your file31 viper.SetConfigType("env")32
33 // Viper reads all the variables from env file and log error if any found34 if err := viper.ReadInConfig(); err != nil {35 log.Fatal("Error reading env file", err)36 }37
38 // Viper unmarshal the loaded env variables into the struct39 if err := viper.Unmarshal(&config); err != nil {40 log.Fatal(err)41 }42 return43}44
45func init() {46 InitEnvConfigs()47}In the envConfigs type, declare the data that will be important to us and expand it as needed.
By reading the configuration in init(), the very first inclusion of our file in the project will make it read the configuration. There are pitfalls in such an implementation, but we'll skip them for now.
Database
Next, we'll need to work with the database itself. I really like the ORM by uptrace, called bun. Moreover, I have been a fan since the days of go-pg by the same team. Therefore, I will use this library as the foundation. It doesn't bind you to anything, but it simplifies life in many aspects.
31go get github.com/uptrace/bun2go get github.com/uptrace/bun/dialect/pgdialect3go get github.com/uptrace/bun/driver/pgdriver
We'll also add uuid right away since we will use them for typing identifiers.
11go get github.com/google/uuid
Now it's time to create a small abstraction for working with the database.
Add a file and a new package at internal/db/db.go
151package db2
3import (4 "database/sql"5 "github.com/uptrace/bun"6 "github.com/uptrace/bun/dialect/pgdialect"7 "github.com/uptrace/bun/driver/pgdriver"8 "example-event-sourcing/internal/config"9)10
11func Connect() *bun.DB {12 sqlDB := sql.OpenDB(pgdriver.NewConnector(pgdriver.WithDSN(config.EnvConfigs.DbDsn)))13 db := bun.NewDB(sqlDB, pgdialect.New())14 return db15}In the future, this file can be expanded and gain additional functions, plus it will make it easier to pass dependencies throughout the project.
Now let's address migrations right away, as I don't want to pull in any additional tools for this, and bun has everything we need.
Create a new file cmd/migrations.go with the following content:
1571package cmd2
3import (4 "context"5 "example-event-sourcing/internal/db"6 "example-event-sourcing/migrations"7 "fmt"8 "github.com/spf13/cobra"9 "github.com/uptrace/bun"10 "github.com/uptrace/bun/migrate"11 "log"12)13
14const MigrationsGroup = "migrations"15
16var migrationNameSql *string17
18func getMigrator(db *bun.DB) *migrate.Migrator {19 return migrate.NewMigrator(db, migrations.Migrations)20}21
22var migrationGroup = &cobra.Group{23 ID: MigrationsGroup,24 Title: "Migrations",25}26
27var migrateInit = &cobra.Command{28 Use: "migrate/init",29 Short: "create migration tables",30 GroupID: MigrationsGroup,31 Run: func(cmd *cobra.Command, args []string) {32 database := db.Connect()33 defer func(database *bun.DB) {34 err := database.Close()35 if err != nil {36 panic(err)37 }38 }(database)39 migrator := getMigrator(database)40 c := context.Background()41 err := migrator.Init(c)42 if err != nil {43 log.Fatalln(err.Error())44 }45 },46}47
48var migrateUp = &cobra.Command{49 Use: "migrate/up",50 Short: "migrate database",51 GroupID: MigrationsGroup,52 Run: func(cmd *cobra.Command, args []string) {53 database := db.Connect()54 defer func(database *bun.DB) {55 err := database.Close()56 if err != nil {57 panic(err)58 }59 }(database)60 migrator := getMigrator(database)61 c := context.Background()62
63 if err := migrator.Lock(c); err != nil {64 log.Fatalln(err.Error())65 }66 defer func(migrator *migrate.Migrator, ctx context.Context) {67 err := migrator.Unlock(ctx)68 if err != nil {69 log.Fatalln(err.Error())70 }71 }(migrator, c)72
73 group, err := migrator.Migrate(c)74 if err != nil {75 log.Fatalln(err.Error())76 }77 if group.IsZero() {78 fmt.Printf("there are no new migrations to run (database is up to date)\n")79 }80 fmt.Printf("migrated to %s\n", group)81 },82}83
84var migrateDown = &cobra.Command{85 Use: "migrate/down",86 Short: "rollback the last migration group",87 GroupID: MigrationsGroup,88 Run: func(cmd *cobra.Command, args []string) {89 database := db.Connect()90 defer func(database *bun.DB) {91 err := database.Close()92 if err != nil {93 panic(err)94 }95 }(database)96 migrator := getMigrator(database)97 c := context.Background()98
99 if err := migrator.Lock(c); err != nil {100 log.Fatalln(err.Error())101 }102 defer func(migrator *migrate.Migrator, ctx context.Context) {103 err := migrator.Unlock(ctx)104 if err != nil {105 log.Fatalln(err.Error())106 }107 }(migrator, c)108
109 group, err := migrator.Rollback(c)110 if err != nil {111 log.Fatalln(err.Error())112 }113 if group.IsZero() {114 fmt.Printf("there are no groups to roll back\n")115 }116 fmt.Printf("rolled back %s\n", group)117 },118}119
120var migrateCreateSql = &cobra.Command{121 Use: "migrate/create_sql",122 Short: "create up and down SQL migrations",123 GroupID: MigrationsGroup,124 Run: func(cmd *cobra.Command, args []string) {125 database := db.Connect()126 defer func(database *bun.DB) {127 err := database.Close()128 if err != nil {129 panic(err)130 }131 }(database)132 migrator := getMigrator(database)133 c := context.Background()134 if migrationNameSql == nil {135 log.Fatalln("name not specified")136 }137 files, err := migrator.CreateSQLMigrations(c, *migrationNameSql)138 if err != nil {139 log.Fatalln(err.Error())140 }141
142 for _, mf := range files {143 fmt.Printf("created migration %s (%s)\n", mf.Name, mf.Path)144 }145
146 },147}148
149func init() {150 rootCmd.AddGroup(migrationGroup)151 rootCmd.AddCommand(migrateInit)152 rootCmd.AddCommand(migrateUp)153 rootCmd.AddCommand(migrateDown)154 rootCmd.AddCommand(migrateCreateSql)155
156 migrationNameSql = migrateCreateSql.Flags().StringP("name", "n", "", "migration name")157}Now you have a set of commands that will help with migrations. This is not an exhaustive list but sufficient for the purpose of this example. For expanding the list of commands, refer to bun's implementation examples.
You also need to create the migrations folder ./migrations and place a main.go file there.
111package migrations2
3import "github.com/uptrace/bun/migrate"4
5var Migrations = migrate.NewMigrations()6
7func init() {8 if err := Migrations.DiscoverCaller(); err != nil {9 panic(err)10 }11}Getting Everything Ready for Message Handling
To do this, create a new file and package internal/event_listener/event_listener.go
541package event_listener2
3import (4 "context"5 "github.com/uptrace/bun"6 "github.com/uptrace/bun/driver/pgdriver"7 "log"8 "strings"9)10
11const (12 EventsCreated = "events:created"13)14
15type EventListener struct {16 db *bun.DB17 listener *pgdriver.Listener18 retryCounter map[string]int19}20
21func New(db *bun.DB) *EventListener {22 return &EventListener{db: db, listener: pgdriver.NewListener(db), retryCounter: make(map[string]int)}23}24
25func (el *EventListener) Listen(ctx context.Context, channel string, callback func(string) error) {26 if err := el.listener.Listen(ctx, channel); err != nil {27 panic(err)28 }29
30 for notification := range el.listener.Channel() {31 err := callback(notification.Payload)32 if err != nil && !strings.Contains(err.Error(), `duplicate key value violates unique constraint "locker_pk"`) {33 log.Println(err)34 if _, ok := el.retryCounter[notification.Payload]; !ok {35 el.retryCounter[notification.Payload] = 036 }37 if el.retryCounter[notification.Payload] < 3 {38 el.retryCounter[notification.Payload]++39 el.Notify(ctx, channel, notification.Payload)40 }41 } else {42 // fixme unsafe, but will see how it goes43 go func() {44 delete(el.retryCounter, notification.Payload)45 }()46 }47 }48}49
50func (el *EventListener) Notify(ctx context.Context, channel string, payload string) {51 if err := pgdriver.Notify(ctx, el.db, channel, payload); err != nil {52 panic(err)53 }54}Also, place helpers.go alongside it.
181package event_listener2
3import (4 "strconv"5 "strings"6)7
8func ExtractIdAndTypeFromPayload(payload string) (string, int, string) {9 data := strings.Split(payload, ",")10 if len(data) == 3 {11 eventTypeID, err := strconv.Atoi(data[1])12 if err != nil {13 return "", 0, ""14 }15 return data[0], eventTypeID, data[2]16 }17 return "", 0, ""18}This file will help us parse what the trigger function will send us later on.
Http Handlers
Now let's prepare everything to launch the web server. I will use gin as one of the popular routers and the one that is most convenient for me.
11go get github.com/gin-gonic/gin
Create another package and file internal/router/router.go.
301package router2
3import (4 "github.com/gin-gonic/gin"5 "example-event-sourcing/internal/config"6)7
8type Router struct {9 router *gin.Engine10}11
12func New() *Router {13 return &Router{router: gin.Default()}14}15
16func (r *Router) AddMutationRoutes(routes map[string]gin.HandlerFunc) {17 for path, handler := range routes {18 r.router.POST(path, handler)19 }20}21
22func (r *Router) AddQueryRoutes(routes map[string]gin.HandlerFunc) {23 for path, handler := range routes {24 r.router.GET(path, handler)25 }26}27
28func (r *Router) Run() {29 r.router.Run(config.EnvConfigs.AppServerPort)30}Again, you can expand on this idea and add anything you need here as you see fit. CORS, default routes, etc.
Abstractions and Interfaces
Great, we're almost done with the preparatory work.
Let's add some basic interfaces and models that we will need. To do this, create a package and file internal/aggregates/models.go and place the following in it:
421package aggregates2
3import (4 "context"5 "encoding/json"6 "github.com/gin-gonic/gin"7 "github.com/google/uuid"8 "github.com/uptrace/bun"9 "time"10)11
12type Domain interface {13 Run()14 QueryRoutes() map[string]gin.HandlerFunc15 MutationRoutes() map[string]gin.HandlerFunc16}17
18type Aggregate interface {19 GetID() string20}21
22type Event struct {23 bun.BaseModel `bun:"table:events,alias:e"`24 ID string `bun:"id" json:"id"`25 TypeID int `bun:"type_id" json:"type_id"`26 AggregateID string `bun:"aggregate_id" json:"aggregate_id"`27 Payload json.RawMessage `bun:"payload" json:"payload"`28 CreatedAt time.Time `bun:"created_at" json:"created_at"`29}30
31type Locker struct {32 bun.BaseModel `bun:"table:locker,alias:loc"`33 EventID uuid.UUID `bun:"event_id,type:uuid" json:"event_id"`34 AggregateID uuid.UUID `bun:"aggregate_id,type:uuid" json:"aggregate_id"`35 LockDomain string `bun:"lock_domain" json:"lock_domain"`36}37
38type AggregateEvent int39
40type EventDelete struct {41 ID string `json:"id"`42}Here you see:
an interface for the domain package, which will need to implement several functions, about which I will explain later.
an interface for the aggregate.
a basic model for the event.
a structure for the lock table, about which I will also tell you a bit later.
and a template for event types.
as well as a basic event type for deletion.
If something seems strange for now, wait a moment; soon everything will become clear.
Now let's add a basic repository for handling event queries.
Create another package with a file internal/repositories/event_repository.go.
261package repositories2
3import (4 "context"5 "github.com/uptrace/bun"6 "example-event-sourcing/internal/aggregates"7)8
9type EventRepository struct {10 db *bun.DB11}12
13func NewEventRepository(db *bun.DB) *EventRepository {14 return &EventRepository{db: db}15}16
17func (r *EventRepository) GetEventByIdAndType(ctx context.Context, id string, eventType int) (*aggregates.Event, error) {18 events := &aggregates.Event{}19 err := r.db.NewSelect().Model(events).Where("id = ? and type_id = ?", id, eventType).Scan(ctx)20 return events, err21}22
23func (r *EventRepository) SaveEvent(ctx context.Context, event *aggregates.Event) (*aggregates.Event, error) {24 _, err := r.db.NewInsert().Model(event).Exec(ctx)25 return event, err26}Let's also add a common handler for events in the package internal/handlers/event_handlers.go.
321package handlers2
3import (4 "github.com/gin-gonic/gin"5 "example-event-sourcing/internal/aggregates"6 "example-event-sourcing/internal/repositories"7)8
9type EventHandlers struct {10 eventRepository *repositories.EventRepository11}12
13func NewEventHandlers(eventRepository *repositories.EventRepository) *EventHandlers {14 return &EventHandlers{15 eventRepository: eventRepository,16 }17}18
19func (e *EventHandlers) SaveEvent(c *gin.Context) {20 event := &aggregates.Event{}21 err := c.BindJSON(event)22 if err != nil {23 c.JSON(500, gin.H{24 "error": err.Error(),25 })26 return27 }28 _, err = e.eventRepository.SaveEvent(c, event)29 c.JSON(200, gin.H{30 "result": "Event saved",31 })32}Domain Packages
In my worldview, someday all this code might need to be split into microservices, which means it would be logical to separate domains from each other right away. Who knows, they might end up running in different containers. This will simply facilitate refactoring in the future. This step is not mandatory and can be simplified, but I'll leave everything as it is.
A domain package is a package containing all models, database queries, route handlers, and reference information for a specific domain.
Let's imagine that we currently have only one entity for the example - users. So, we'll operate with it.
Create a package with the following structure:
41internal/domains/users/aggregator/users.go2internal/domains/users/models/users.go3internal/domains/users/repository/users.go4internal/domains/users/users.go
In the file internal/domains/users/models/users.go, let's declare our data representation model:
201package models2
3import (4 "github.com/google/uuid"5 "github.com/uptrace/bun"6)7
8type User struct {9 bun.BaseModel `bun:"table:users,alias:u"`10
11 ID uuid.UUID `bun:"id,type:uuid" json:"id"`12 Username string `bun:"username" json:"username"`13 Password string `bun:"password" json:"-"`14 Email string `bun:"email" json:"email"`15
16}17
18func (u *User) GetID() string {19 return u.ID.String()20}n the file internal/domains/users/repository/users.go, we'll add database queries:
991package repository2
3import (4 "context"5 "github.com/google/uuid"6 "github.com/uptrace/bun"7 "example-event-sourcing/internal/aggregates"8 "example-event-sourcing/internal/domains/users/models"9)10
11type Repository struct {12 db *bun.DB13}14
15func New(db *bun.DB) *Repository {16 return &Repository{db: db}17}18
19func (r *Repository) Find(ctx context.Context, id string) (aggregates.Aggregate, error) {20 user := &models.User{}21 err := r.db.NewSelect().Model(user).Where("id = ?", id).Scan(ctx)22 if err != nil {23 return nil, err24 }25 return user, nil26}27
28func (r *Repository) Save(ctx context.Context, aggregate aggregates.Aggregate, eventID string) error {29 user := aggregate.(*models.User)30 tx, err := r.db.BeginTx(ctx, nil)31 if err != nil {32 tx.Rollback()33 return err34 }35 _, err = r.Find(ctx, user.GetID())36 if err != nil {37 _, err := tx.NewInsert().Model(user).Exec(ctx)38 if err != nil {39 tx.Rollback()40 return err41 }42 }43 _, err = tx.NewUpdate().Model(user).Where("id = ?", user.ID).Exec(ctx)44 if err != nil {45 tx.Rollback()46 return err47 }48
49 _, err = tx.NewInsert().Model(&aggregates.Locker{50 EventID: uuid.MustParse(eventID),51 AggregateID: uuid.MustParse(aggregate.GetID()),52 LockDomain: "users",53 }).Exec(ctx)54
55 if err != nil {56 tx.Rollback()57 return err58 }59
60 return tx.Commit()61}62
63func (r *Repository) Delete(ctx context.Context, id, eventID string) error {64 tx, err := r.db.BeginTx(ctx, nil)65 if err != nil {66 tx.Rollback()67 return err68 }69 _, err = tx.NewDelete().Model(&models.User{}).Where("id = ?", id).Exec(ctx)70 if err != nil {71 tx.Rollback()72 return err73 }74 _, err = tx.NewInsert().Model(&aggregates.Locker{75 EventID: uuid.MustParse(eventID),76 AggregateID: uuid.MustParse(id),77 LockDomain: "users",78 }).Exec(ctx)79
80 if err != nil {81 tx.Rollback()82 return err83 }84 return tx.Commit()85}86
87func (r *Repository) All(ctx context.Context) ([]aggregates.Aggregate, error) {88 data := make([]aggregates.Aggregate, 0)89 users := make([]*models.User, 0)90 err := r.db.NewSelect().Model(&users).Scan(ctx)91 if err != nil {92 return nil, err93 }94 for _, user := range users {95 data = append(data, user)96 }97
98 return data, nil99}There are only 4 of them:
Retrieve a record by ID
Retrieve all records
Save data
Delete data
And now it's time to explain the lock table and why our Save and Delete queries are implemented this way.
The setup looks like this:
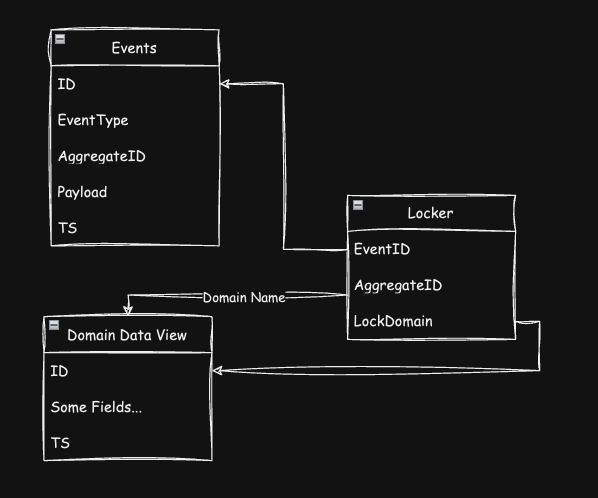
It's needed to protect data from double overwriting in case of duplicate events for some reason or if multiple subscribers are running (for example, application replicas).
The logic is such that during data update, insertion, or deletion, we rely on a combination of aggregate identifiers, event names, and domain data view names (essentially tables for insertion in the current example). And the transaction for modifying data in the view, besides updating the table itself, requires inserting data into the lock table. If the composite primary key from the three fields mentioned above already exists, the transaction will not be executed, and we won't unnecessarily rebuild the data. This is just one implementation option for protection, not the best one, but sufficient for a start.
In addition, this lock table will serve as a source of truth regarding whether all events have been applied to the view.
Also, the hash sum of aggregate keys can serve as the key to data revision, which we don't need right now but may come in handy in the future.
Now let's add the event handling logic itself.
In the file internal/domains/users/aggregator/users.go, place the following code:
1541package aggregator2
3import (4 "context"5 "encoding/json"6 "github.com/uptrace/bun"7 "example-event-sourcing/internal/aggregates"8 "example-event-sourcing/internal/domains/users/models"9 "example-event-sourcing/internal/domains/users/repository"10 "example-event-sourcing/internal/event_listener"11 "example-event-sourcing/internal/repositories"12)13
14const Factor = 100015
16const (17 UsersCreated aggregates.AggregateEvent = iota + Factor18 UsersUpdatePassword19 UsersUpdateUsername20 UsersUpdateEmail21 UsersDeleted22
23 UsersUnusedEvent24)25
26type EventUpdatePassword struct {27 Password string `json:"password"`28}29
30type EventUpdateUsername struct {31 Username string `json:"username"`32}33
34type EventUpdateEmail struct {35 Email string `json:"email"`36}37
38func ConvertFromInt(in int) aggregates.AggregateEvent {39 return aggregates.AggregateEvent(in)40}41
42func IsEventTypeValid(eventType aggregates.AggregateEvent) bool {43 return eventType >= UsersCreated && eventType < UsersUnusedEvent44}45
46type Aggregator struct {47 db *bun.DB48 eventListener *event_listener.EventListener49 repository *repository.Repository50 eventRepository *repositories.EventRepository51}52
53func New(54 db *bun.DB,55 eventListener *event_listener.EventListener,56 repository *repository.Repository,57 eventRepository *repositories.EventRepository,58) *Aggregator {59 return &Aggregator{60 db: db,61 eventListener: eventListener,62 repository: repository,63 eventRepository: eventRepository,64 }65}66
67func (a *Aggregator) Run() {68 ctx := context.Background()69 a.eventListener.Listen(ctx, event_listener.EventsCreated, a.buildUsers)70}71
72func (a *Aggregator) GetUserByID(ctx context.Context, id string) (*models.User, error) {73 userAggregate, err := a.repository.Find(ctx, id)74 if err != nil {75 return nil, err76 }77 user := userAggregate.(*models.User)78 return user, nil79}80
81func (a *Aggregator) ExtractUserAndUpdatedModel(ctx context.Context, eventID string, eventType int, aggregateID string, eventUpdate interface{}) (*models.User, interface{}, error) {82 event, err := a.eventRepository.GetEventByIdAndType(ctx, eventID, eventType)83 if err != nil {84 return nil, nil, err85 }86
87 user, err := a.GetUserByID(ctx, aggregateID)88 if err != nil {89 return nil, nil, err90 }91
92 payloadJson := event.Payload93 err = json.Unmarshal(payloadJson, eventUpdate)94 if err != nil {95 return nil, nil, err96 }97
98 return user, eventUpdate, nil99}100
101func (a *Aggregator) buildUsers(payload string) error {102 ctx := context.Background()103 id, eventType, aggregateID := event_listener.ExtractIdAndTypeFromPayload(payload)104 convertedType := ConvertFromInt(eventType)105 if !IsEventTypeValid(convertedType) {106 return nil107 }108 switch convertedType {109 case UsersCreated:110 event, err := a.eventRepository.GetEventByIdAndType(ctx, id, eventType)111 if err != nil {112 return err113 }114 user := &models.User{}115 payloadJson := event.Payload116 err = json.Unmarshal(payloadJson, user)117 if err != nil {118 return err119 }120 return a.repository.Save(ctx, user, id)121
122 case UsersUpdatePassword:123 user, userUpdate, err := a.ExtractUserAndUpdatedModel(ctx, id, eventType, aggregateID, &EventUpdatePassword{})124 if err != nil {125 return err126 }127 user.Password = userUpdate.(*EventUpdatePassword).Password128 return a.repository.Save(ctx, user, id)129 case UsersUpdateEmail:130 user, userUpdate, err := a.ExtractUserAndUpdatedModel(ctx, id, eventType, aggregateID, &EventUpdateEmail{})131 if err != nil {132 return err133 }134 user.Email = userUpdate.(*EventUpdateEmail).Email135 return a.repository.Save(ctx, user, id)136 case UsersUpdateUsername:137 user, userUpdate, err := a.ExtractUserAndUpdatedModel(ctx, id, eventType, aggregateID, &EventUpdateUsername{})138 if err != nil {139 return err140 }141 user.Username = userUpdate.(*EventUpdateUsername).Username142 return a.repository.Save(ctx, user, id)143 case UsersDeleted:144 user, _, err := a.ExtractUserAndUpdatedModel(ctx, id, eventType, aggregateID, &aggregates.EventDelete{})145 if err != nil {146 return err147 }148 return a.repository.Delete(ctx, user.ID.String(), id)149 default:150 panic("unhandled default case")151 }152
153 return nil154}Here, we're primarily concerned with the Run() function, which invokes some logic for building the view.
The essence lies in understanding which event type we received, executing some logic, and calling the Save method. In practice, it's recommended to distribute the switch case bodies across different functions, of course.
The main file left is internal/domains/users/users.go.
Essentially, it should implement the Domain interface.
681package users2
3import (4 "github.com/gin-gonic/gin"5 "github.com/uptrace/bun"6 "example-event-sourcing/internal/aggregates"7 "example-event-sourcing/internal/domains/users/aggregator"8 "example-event-sourcing/internal/domains/users/models"9 "example-event-sourcing/internal/domains/users/repository"10 "example-event-sourcing/internal/event_listener"11 "example-event-sourcing/internal/handlers"12 "example-event-sourcing/internal/repositories"13)14
15type UserDomain struct {16 db *bun.DB17 eventListener *event_listener.EventListener18 aggregator *aggregator.Aggregator19 repository *repository.Repository20 eventRepository *repositories.EventRepository21 eventHandlers *handlers.EventHandlers22}23
24func New(25 db *bun.DB,26 eventListener *event_listener.EventListener,27 eventRepository *repositories.EventRepository,28 eventHandlers *handlers.EventHandlers,29) *UserDomain {30 repo := repository.New(db)31 agg := aggregator.New(db, eventListener, repo, eventRepository)32
33 return &UserDomain{34 db: db,35 eventListener: eventListener,36 repository: repo,37 aggregator: agg,38 eventRepository: eventRepository,39 eventHandlers: eventHandlers,40 }41}42
43func (u *UserDomain) Run() {44 u.aggregator.Run()45}46
47func (u *UserDomain) QueryRoutes() map[string]gin.HandlerFunc {48 routes := make(map[string]gin.HandlerFunc)49 routes["/users"] = func(c *gin.Context) {50 data, err := u.repository.All(c)51 if err != nil {52 c.JSON(500, gin.H{53 "error": err.Error(),54 })55 return56 }57 c.JSON(200, gin.H{58 "result": data,59 })60 }61 return routes62}63
64func (u *UserDomain) MutationRoutes() map[string]gin.HandlerFunc {65 routes := make(map[string]gin.HandlerFunc)66 routes["/users"] = u.eventHandlers.SaveEvent67 return routes68}Here it's all quite straightforward. Except for why we separated the event recording into a separate route? It's not necessary, but again, it's more correct in terms of further developing the idea because different routes might likely have different permissions, and having this level of abstraction might be more convenient than just having one endpoint for dumping all events. Again, the final implementation is up to you :-)
Migrations
We're getting closer to working directly with the database, so it's time to set up some environment. To do this, let's add a docker-compose.yaml file to the project root, where we'll simply spin up a default PostgreSQL container.
171version'3.1'2
3volumes4 example-event-sourcing_pg_db5
6services7 example-event-sourcing_db8 imagepostgres9 restartalways10 environment11POSTGRES_PASSWORD=postgres12POSTGRES_USER=postgres13POSTGRES_DB=example14 volumes15example-event-sourcing_pg_db:/var/lib/postgresql/data16 ports17$POSTGRES_PORT:-5434:5432And now, knowing the credentials, let's create a .env file in the project root.
21DB_DSN=postgres://postgres:postgres@localhost:5434/example?sslmode=disable2APP_SERVER_PORT=":7755"
Let's start our database container:
11docker-compose up -d
Next, we need to initialize the migrations themselves so that all the necessary tables are created in the database:
11go run main.go migrate/init
And now let's add new migrations through:
11go run main.go migrate/create_sql -n events
This will add two files to the migrations folder, in the format YYYYMMDDHHmmss_events.(up|down).sql.
In the added up file, insert our structure for working with events.
321CREATE TABLE IF NOT EXISTS events2(3 id uuid not null,4 type_id smallserial not null,5 aggregate_id uuid not null,6 payload json not null,7 created_at timestamp default CURRENT_TIMESTAMP not null,8 constraint events_pk9 primary key (id, aggregate_id, type_id)10);11
12CREATE FUNCTION events_after_insert_trigger()13 RETURNS TRIGGER AS $$14BEGIN15 PERFORM pg_notify('events:created', CONCAT(NEW.id::text, ',', NEW.type_id::text, ',', NEW.aggregate_id::text));16 RETURN NULL;17END;18$$19 LANGUAGE plpgsql;20
21CREATE TRIGGER events_after_insert_trigger22 AFTER INSERT ON events23 FOR EACH ROW EXECUTE PROCEDURE events_after_insert_trigger();24
25CREATE TABLE IF NOT EXISTS locker26(27 event_id uuid not null,28 aggregate_id uuid not null,29 lock_domain varchar(50) not null,30 constraint locker_pk31 primary key (event_id, aggregate_id, lock_domain)32);The crux here is the line where we send the format string uuid,int,uuid to the events:created channel. And it's precisely this format that our helper in the internal/event_listener/helpers.go file parses.
11pg_notify('events:created', CONCAT(NEW.id::text, ',', NEW.type_id::text, ',', NEW.aggregate_id::text));
Again, this can be extended and modified as needed.
For the down file, the content will be the opposite of the addition.
41DROP TRIGGER IF EXISTS events_after_insert_trigger ON events;2DROP FUNCTION IF EXISTS events_after_insert_trigger();3DROP TABLE IF EXISTS locker;4DROP TABLE IF EXISTS events;Don't forget about the table representing the user domain.
11go run main.go migrate/create_sql -n users
up:
91CREATE TABLE IF NOT EXISTS users2(3 id uuid4 constraint users_pk5 primary key,6 username varchar(100),7 password varchar(255),8 email varchar(100)9);down:
11DROP TABLE IF EXISTS users;Now, let's add our migrations to the database:
11go run main.go migrate/up
Initializing the Application
And the cherry on top. Now we can fix the code in the cmd/run.go file.
471package cmd2
3import (4 "example-event-sourcing/internal/aggregates"5 "example-event-sourcing/internal/db"6 "example-event-sourcing/internal/domains/users"7 "example-event-sourcing/internal/event_listener"8 "example-event-sourcing/internal/handlers"9 "example-event-sourcing/internal/repositories"10 "example-event-sourcing/internal/router"11 "github.com/spf13/cobra"12 "github.com/uptrace/bun"13)14
15func getAllDomain(dbConnection *bun.DB) []aggregates.Domain {16 eventRepository := repositories.NewEventRepository(dbConnection)17 eventHandlers := handlers.NewEventHandlers(eventRepository)18 eventListener := event_listener.New(dbConnection)19 domains := []aggregates.Domain{20 users.New(dbConnection, eventListener, eventRepository, eventHandlers),21 }22
23 return domains24}25
26// runCmd represents the run command27var runCmd = &cobra.Command{28 Use: "run",29 Short: "Run application",30 Run: func(cmd *cobra.Command, args []string) {31 dbConnection := db.Connect()32 defer dbConnection.Close()33 domains := getAllDomain(dbConnection)34 server := router.New()35 for _, domain := range domains {36 go domain.Run()37 server.AddQueryRoutes(domain.QueryRoutes())38 server.AddMutationRoutes(domain.MutationRoutes())39 }40
41 server.Run()42 },43}44
45func init() {46 rootCmd.AddCommand(runCmd)47}Here, we're interested solely in the moment of forming the list of domains in the getAllDomain function. When expanding functionality, we simply need to add the initialization of another domain to the domains variable.
Now you can run the application:
11go run main.go run
Or build it and run the binary.
If you're using a JetBrains IDE, create a test.http file in the project root and you can play around with API request examples:
361### GET request to example server to featch all users2GET http://localhost:7755/users3
4###5
6### POST request to example server to create a new user7POST http://localhost:7755/users8Content-Type: application/json9
10{11 "id": "000000aa-1111-2222-3333-000000000001",12 "aggregate_id": "100000bb-1111-2222-3333-000000000001",13 "type_id": 1000,14 "payload": {15 "id": "100000bb-1111-2222-3333-000000000001",16 "username": "test",17 "email": "test@test.test"18 }19}20
21###22
23### POST request to example server to update the password for existing aggregate24POST http://localhost:7755/users25Content-Type: application/json26
27{28 "id": "000000aa-1111-2222-3333-000000000002",29 "aggregate_id": "100000bb-1111-2222-3333-000000000001",30 "type_id": 1001,31 "payload": {32 "password": "test_password"33 }34}35
36###Explanation of Identifiers
In the above example, we let the client generate identifiers for the aggregate and for the event upon request. There's an explanation for this:
Automatic generation of identifiers on the backend side is fraught with duplication when the same request is repeated. Therefore, when making requests, the client should take care of generating them themselves. This slightly complicates the logic on the client side, but only by a couple of functions. But the benefits outweigh this.
In particular, this is why I use UUIDs in the example, which in general should minimize collisions in identifier intersections. Using serials and auto-increments in the database would require more logic to filter out duplicate events.
Conclusions
The idea is more than viable, but it has its nuances and peculiarities. Whether to use it or not should be a weighed and considered decision. Don't take it as something good or bad. It's just a variation on the theme, and not the best one in terms of code; it could be written better. But I've tried to convey the idea and show how it could be done.
Have we achieved our goals?
I want to have a minimum of infrastructure ✅
I want to have a mature application architecture from the start ✅
It should be quick to develop ✅
It should be clear and simple, i.e., the list of technologies should be minimal ✅
Okay, but we're definitely not done yet.
Next, let's develop this idea and example in terms of how to avoid spending time on writing specifications and use code generation for interacting with the frontend.